【机器学习算法】如何運用SVM进行歌曲分类
探讨非线性SVM,了解核函数的概念,并利用Python sklearn库中的SVM模块对不同风格的歌曲进行分类(语料及.Py代码下载方式见文章末处)。
1.非线性SVM
此前我们提过SVM处理非线性问题时需要转化为线性问题,再用线性SVM的算法进行求解,所以实质上SVM只能处理线性问题。这里将非线性问题转化为线性问题的方法主要是借助核函数将低维的数据映射到高维空间中,使得数据在高维空间中能够线性可分,如下图所示,图左的样本点无法使用直线分类面来划分,但经过映射变成右图的形式后线性可分。
这种变换可以理解为引入了一个非线性变换函数∅(·)将R^n空间的样本X映射到R^m空间,其中n<<m。可以看到图左其实可以用一个二次曲线来进行划分,方程运算式可以写为:
通过构造一个5维空间,令
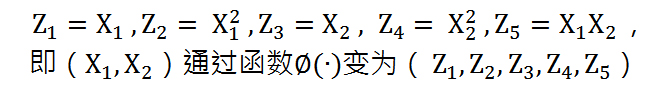
从而变成一个线性可分的问题,此时
然而随着维度的增加,∅(·)函数的计算是非常困难的,甚至会导致维数灾难,故需要引入核函数。核函数能够接收低维空间的向量,计算出经过变换后在高维空间里的向量内积值,而不用先映射到高维空间中再进行内积计算,不用显示的写出映射后的结果。关于核函数的选择,虽然有一些经验的结论,但缺乏比较系统有效的方法,故不进行详细的讨论,多数情况下还是通过多次实验测试的结果来选择最优的核函数。常用的核函数主要有:
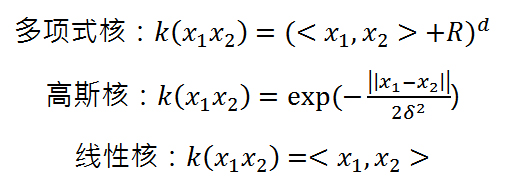
加入核函数后分类判别函数表示为:
根据上节讲到的拉格朗日方程得到对偶目标函数为:
C为加入的惩罚因数,表示对离群点的重视程度。最后根据线性SVM的算法对目标函数进行求解,可以得到分类平面的函数。
当然本文只是用通俗浅显的方式对SVM的知识进行了梳理,如果需要更深层的掌握核函数的运用和SVM的原理,需要大家继续探索,相信通过初步的学习大家能够对SVM算法有个基本的认识。同时非常感谢在网络中对该算法无私分享的朋友(包括文章、图片或著作等),若内容上有冒犯的地方请联系我们修改或删除。
下面我们将分享一个简单的使用SVM算法对歌曲进行分类的实例。
2.利用SVM算法进行歌曲分类
小编首先在歌词网站上爬取了郑源、张信哲、成龙等几位歌手所唱歌曲的歌词,并筛选出爱情类歌曲112首,励志类歌曲94首,保存为songs_content.xlsx文件,并标注了具体的类别标签。下面,我们将利用向量空间模型结合SVM算法对这两类歌曲进行建模和分类。
首先导入后面需要用到的库和函数,对歌词进行预处理,使用jieba库进行分词,分词后的效果如下图所示,并将类别标签保存在label列表。
然后通过计算歌词中全部特征的tf-idf值,将歌词文本转化为向量,构建向量空间模型,得到一个206行4481维的特征向量矩阵。再使用train_test_split函数将样本随机分为训练集和测试集,这里我们取出20%的样本用来测试,另80%的样本用来建模。
构建SVM训练模型,选择参数gamma = 0.001,C为100,核函数默认为rbf核函数,将训练集样本输入模型进行拟合后,再使用该模型对测试集进行预测,通过比较预测结果和实际结果,发现精确率、召回率和f1-score的值都比较低。接下来改变核函数,使用线性核linear试试,得到的模型的精确率为0.875,召回率为0.955,f1-score为0.913。
可以看出,使用线性核函数后模型能够得到较高的精度。当然,感兴趣的朋友也可以通过其他方式对该模型进一步优化,如增加样本、删除一些停用词,使用其他方法对文本特征进行提取或调试模型参数等。
如需下载本文的语料及.py文件,请关注“博易数据”(微信号:boyidata)公众号并发送“code-svm”获取。