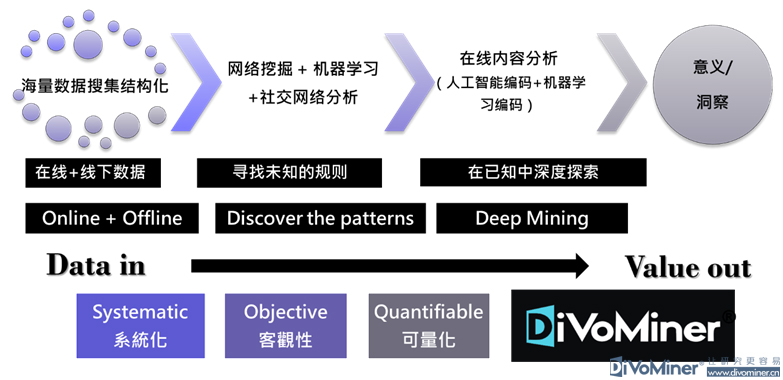
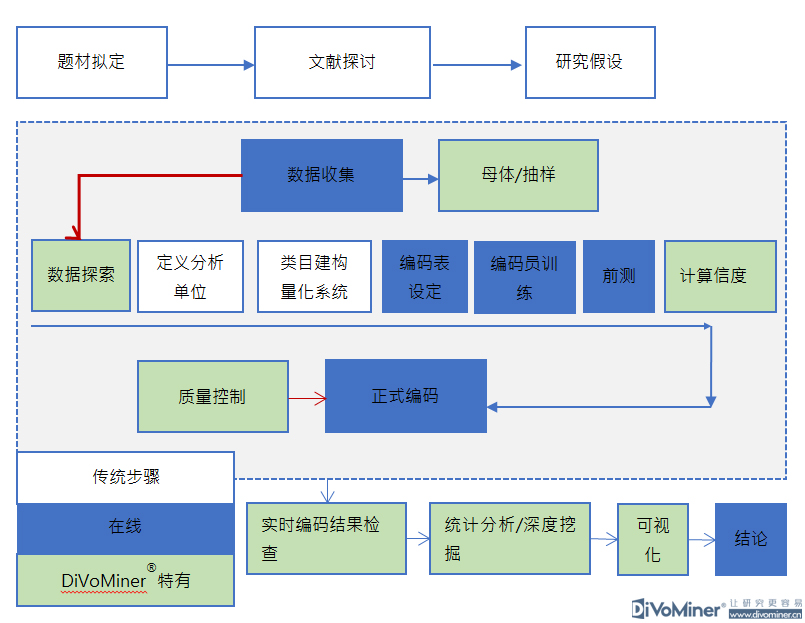
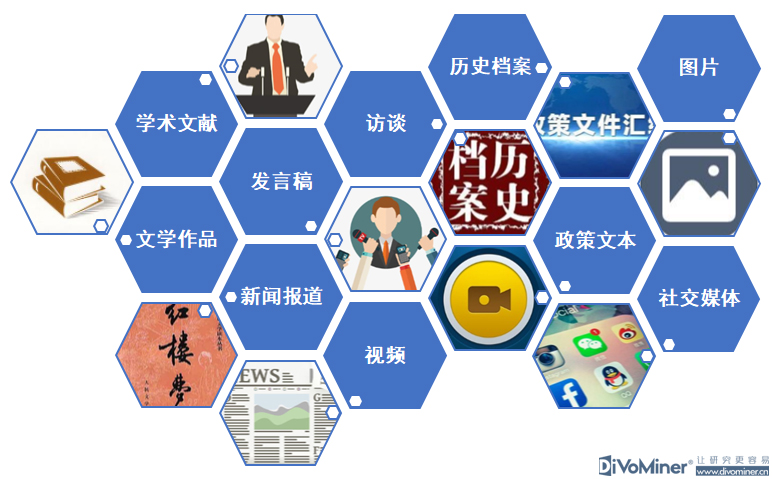
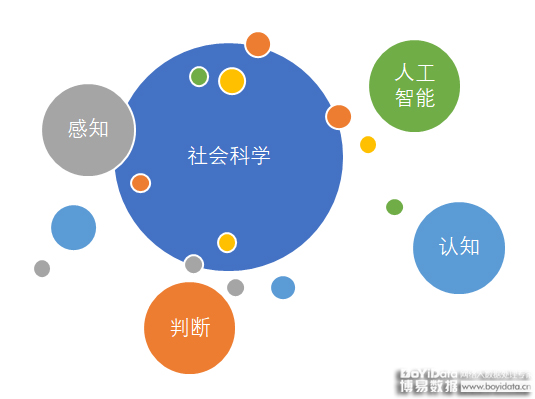
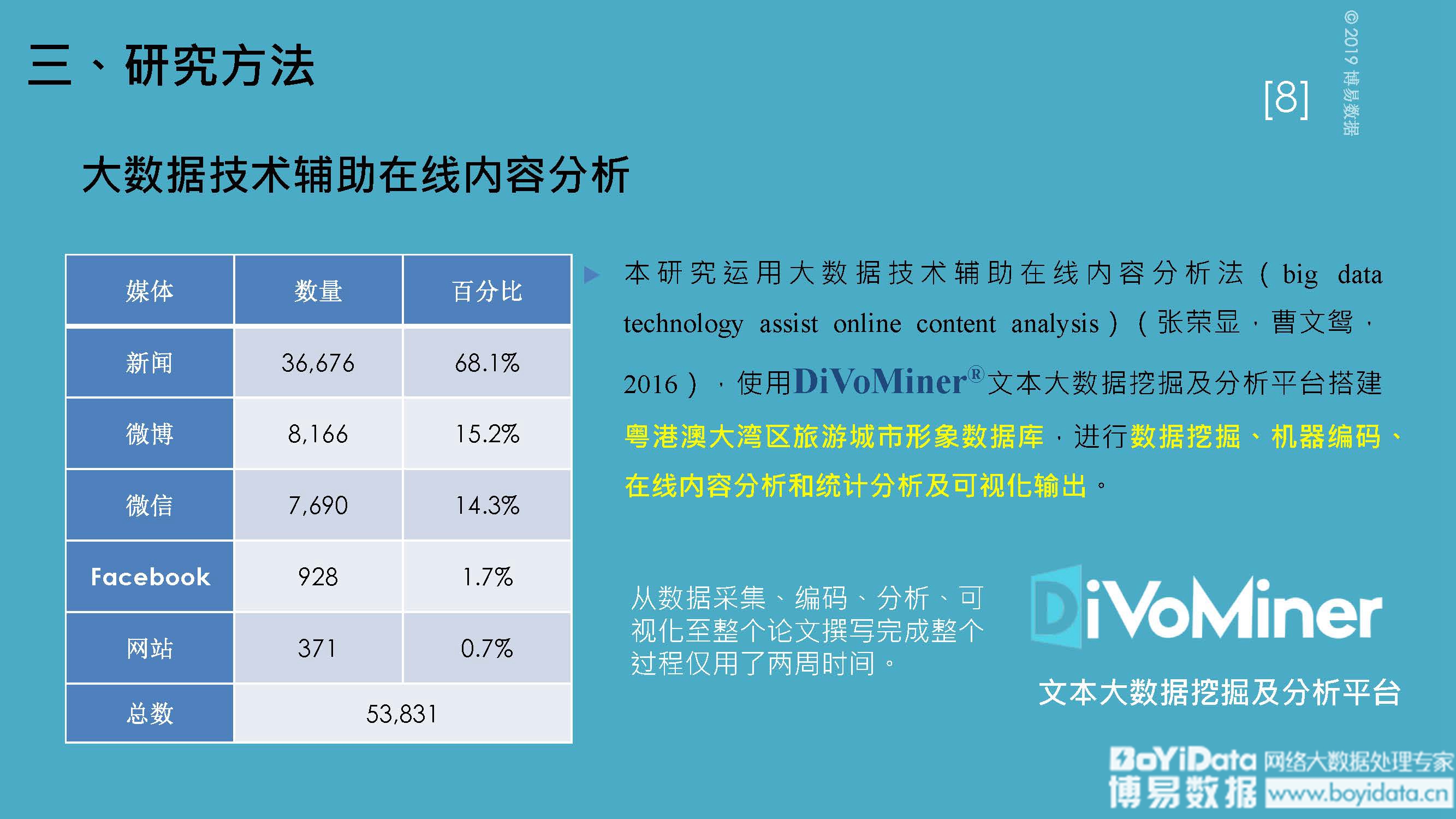
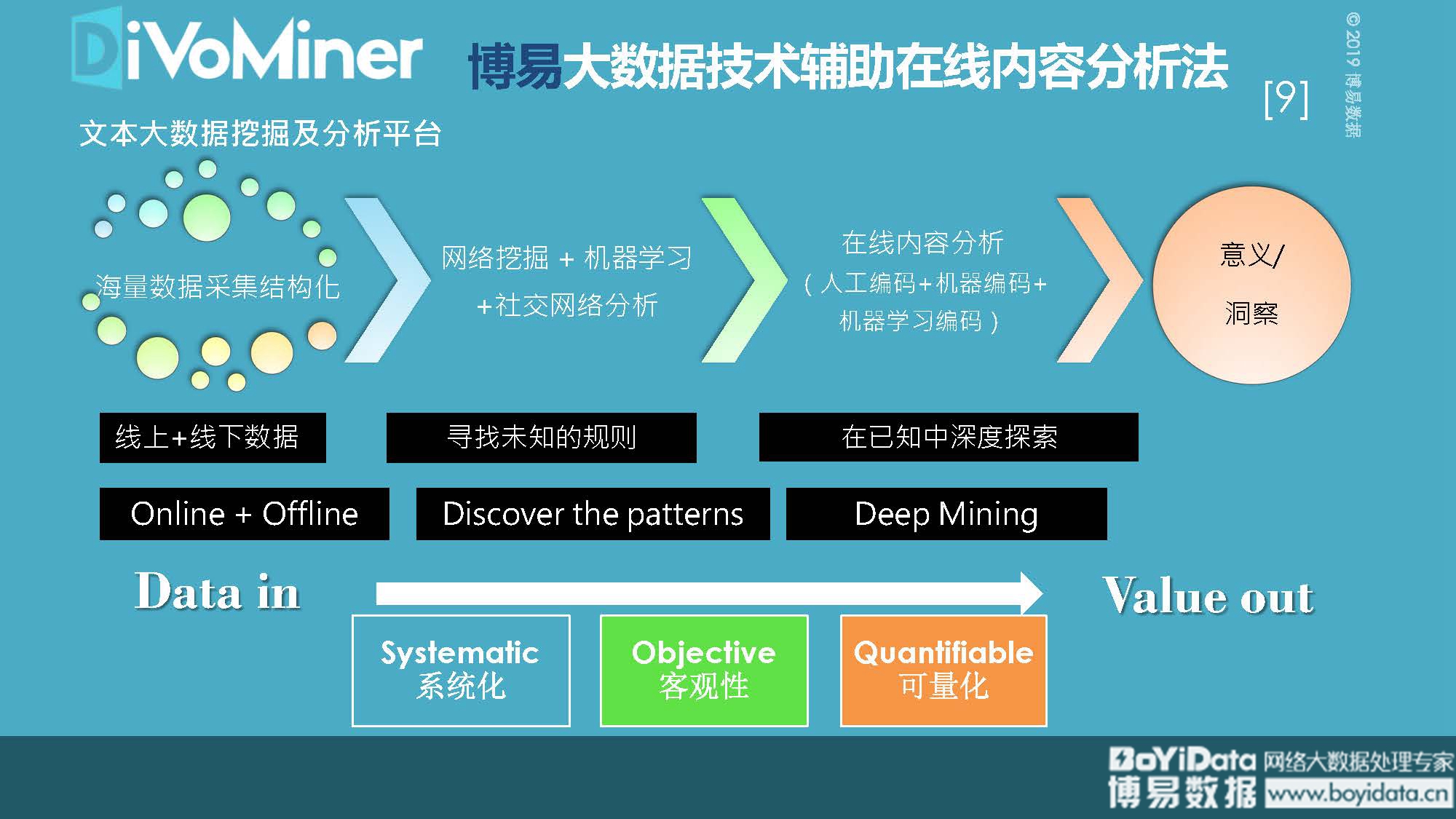
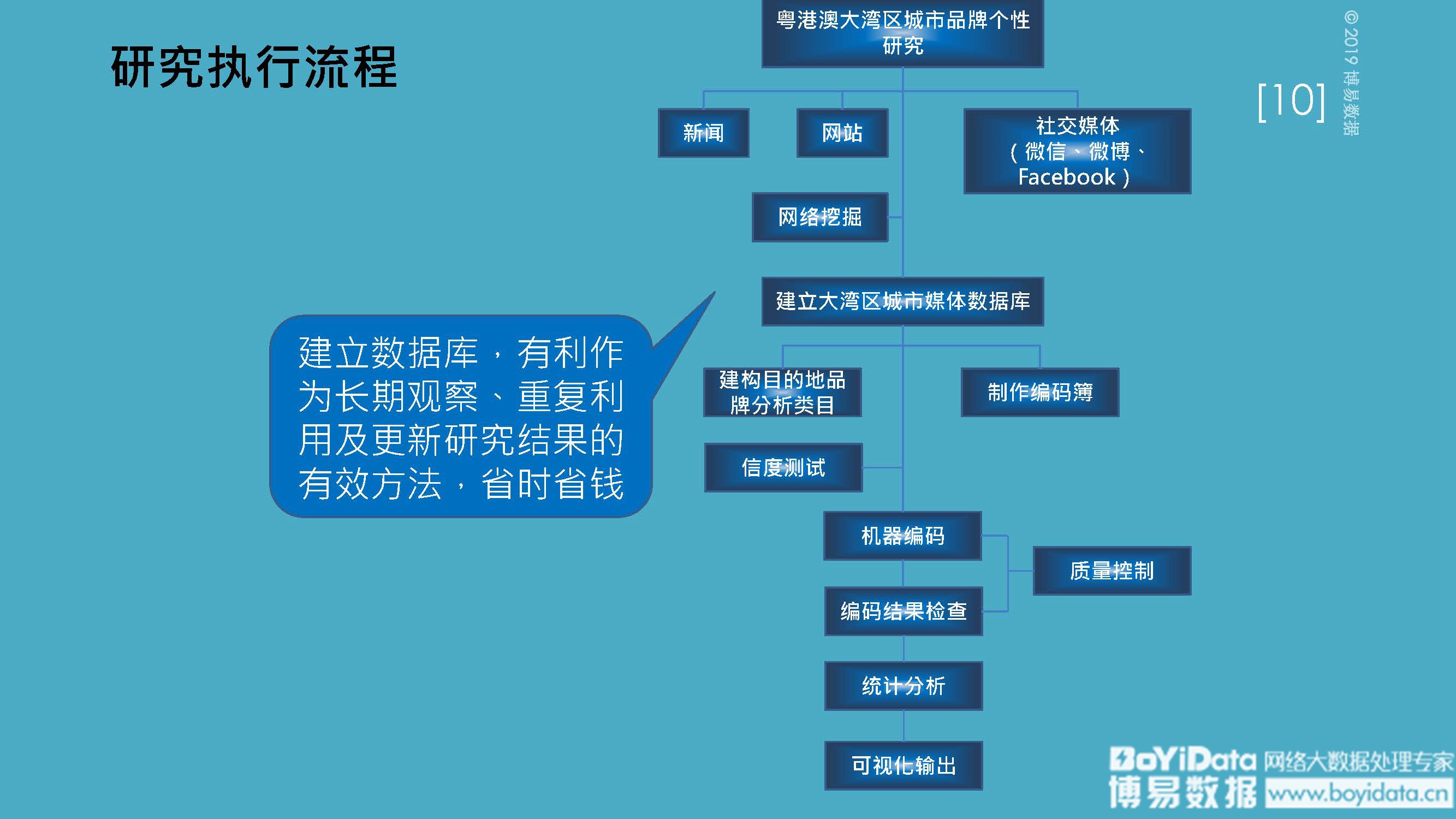
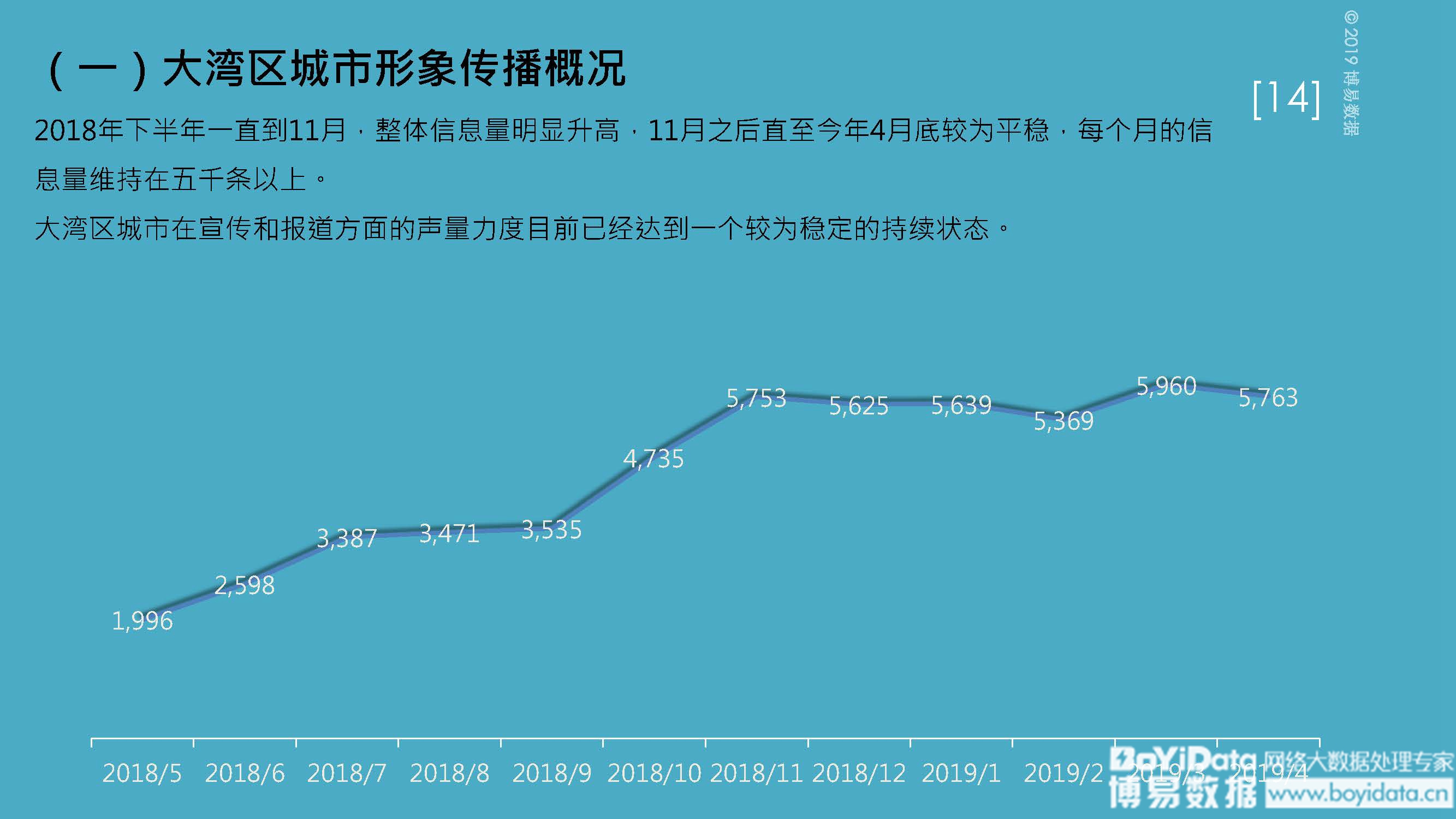
在人人都谈论大数据和人工智能的时代,社会科学研究的未来是否可以与这些新的技术发展结伴而行?这成了困扰当前社会科学领域研究的一大难题。
社会科学是探索人类社会及其发展规律的科学,这一领域涉及哲学、经济学、法学、政治学、社会学、历史学、文学、艺术等学科。随着大数据时代的到来,人工智能、机器学习、深度学习等为社会科学研究带来了新的机遇和视野,但同时也因社会科学领域研究者所掌握的技术、算法的相关知识相对较为薄弱,使得其对人工智能等技术应用望而却步。
人工智能主要指机器以模仿人类智能的方式执行任务,[1]具体来说,可从三个层次理解人工智能。
第一个层面比较泛泛而谈,指机器执行我们通常理解的(human-like understanding)任务的能力。[2]
第二个层面综合了类似人类的多种能力,即机器具有像人类一样感知(sense)、理解(comprehend)、行动(act)、学习(learn)的能力。[3]
第三个层面上升至认知和判断并解决问题的能力,人工智能显示出类似人类的认知能力和执行能力,强调人工智能是一种复杂的技术应用,机器能展示人类的认知功能(human cognitive),如学习、分析和解决问题。[4]
总体来讲,人工智能主要集中在类似人类的感知、认知和判断能力方面的探索和实践。
弱人工智能主要是模拟人的某些特定的技能,智能处理一些特定场景和应用的问题,实际应用领域包括,例如语音识别,图像人脸识别,自然语言处理,信息检索,自动驾驶,智能控制机器人等。
人工智能的发展目前尚停留在弱人工智能阶段,正努力向具有自主意识的强人工智能突破。
那么,当强人工智能应用得以实现后,是否意味着人工智能就可以取代人类呢?
在人工智能的实践和应用中出现过机器战胜人类的AlphaGo,它结合了蒙特卡洛树搜索与深度神经网络(决策网络和数值网络)算法,通过自我学习进行直觉训练,匹配职业棋手的过往棋局中约含3000万步棋着,进行强化学习,以达到甚至超越人类的围棋水平。[6]
在2017年5月,AlphaGo战胜了世界第一棋手柯洁,是围棋界一次人工智能算法成功的尝试,引发了人工智能可以战胜人类的讨论。但AlphaGo在与人类进行围棋对决的过程中,也有“人不可能不出错”的因素。
相比于不断“进化”的AlphaGo,红极一时的索菲亚机器人通过预先录好的脚本应答各种问题,模仿人类的手势和面部表情,并能够与人进行简单的对话交流。2016年,曾登上时尚杂志封面、接受各地媒体访谈,走上机器人巅峰。[7]
虽然索菲亚机器人逼真的外形和快速反应的能力曾经让大家以为具有自我意识的人工智能时代已经到来。但这种只能通过预先设定的脚本进行反应的做法仍然是处于弱人工智能阶段,它还是无法自我思考。
在《哈佛商业评论》(Harvard Business Review)中,有学者总结目前不会被人工智能取代的七大技能[8],指出当前人工智能还无法通过技术或算法达到的能力,这也是目前否定人工智能可以取代人类的原因所在。
多层次的情感处理的能力(Emotional competence)
伦理和道德的判断(An ethical compass)
由此可见,人工智能的实践和应用在目前取得的成果基本上还是停留在一个非自主意识的弱人工智能阶段,机器实现自我意识不是在短时间内就可以达到的,我们能做的是不断提升技术,优化算法,不断提升机器学习和辅助的能力。
因而,我们不应该去问人工智能是否会取代人类,或者计算机能否赢得图灵的模仿游戏这类问题,我们需要机器来做那些人类做不到、做不好的事情,这才是关于人工智能需要去研究的具体问题。[9]只有这样,才能让人工智能真正向惠及人类的实践应用发展。
所以,停止关心机器取代人类的问题,将关注点聚焦在机器如何辅助我们的实践应用中。
在社会科学研究中,人工智能多应用在数据的分析和处理过程中,尤其是对文本数据的意义挖掘和价值洞察。涉及到的文本数据类型多样,包括新闻报道、社交网络的信息、历史档案、访谈文字、文献、政策文档等。过去,在传统的社会科学研究中,都是人工进行文本或者数据的分析和处理,如今,运用人工智能来面对文本或数据的时候,如何从文本中来理解人的行为和想法?
人工智能在文本大数据的挖掘与分析中的应用,集中在媒体监测和趋势预测等方面。以舆情领域的研究和实践为例,当前很多应用是处于收集资料的阶段,即是人工智能的感知层面。利用机器获取数据涉及到数据覆盖度的问题,是机器获取的数据是否齐全或者是否具有代表性以及获取到的数据质量的考量,这与人工智能对于数据获取的感知能力有关。
认知,相当于机器通过对自然语言文本的理解,进行智能的自动化归类和分析,实务上来说,就是如何去测量,从文本中得到意义和洞察结果。
判断,相当于了解了文本之后所作出的决策和行为。也就是说,怎么解释、分析、挖掘研究发现,协助用户可以做出正确的判断,以为后续采取行动做指引和参考。
这三部曲,就是利用人工智能辅助进行文本数据的挖掘及分析时需要考虑的问题,这也是当前文本大数据挖掘和分析过程中遇到的三大挑战。
聚焦在自然语言处理方面,人工智能在文本大数据挖掘的方面目前已经有了一些应用。
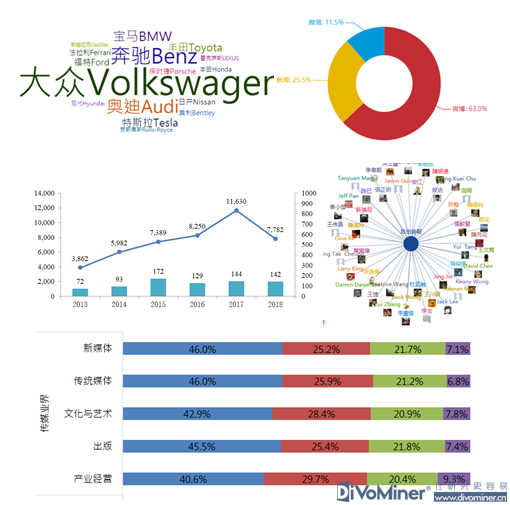
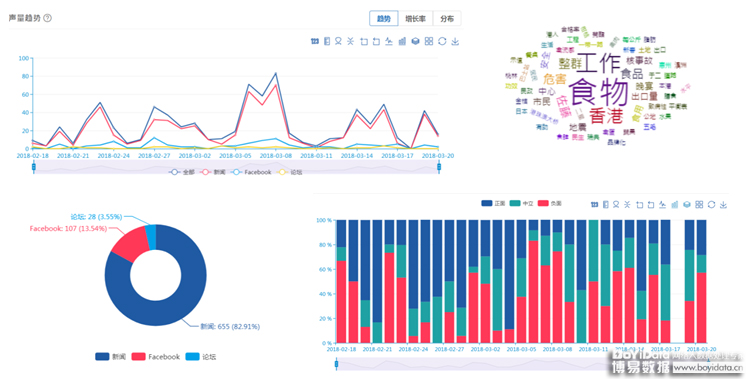
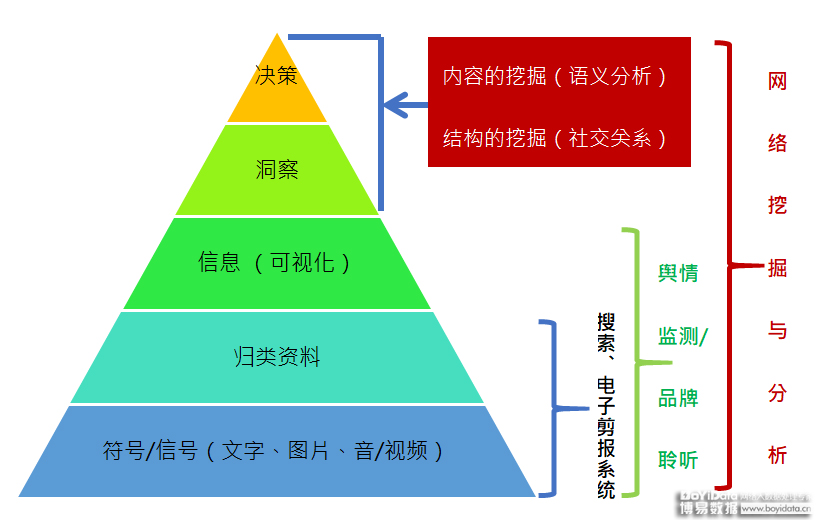
以舆情系统为例,当前主要以描述KPI的结果为主(如图1所示),如数据来源、内容的分类、点赞数、跟帖数、分享量、热度,情感分析、情绪分析等。这些都是机器感知的一部分,但目前这种分析能力还只是停留在初步的阶段,仍然需要进一步深度的挖掘和分析。
无论是舆情研究还是其他的文本研究中,认知层面涉及到的问题是目前机器比较难以解决的,尤其是需要考量中文千变万化的语境和上下文复杂的场景。对于机器来说,针对语境和场景进行理解需要大量的常识,这也是目前人工智能应用较难突破的部分,但是语境和场景也恰巧是文本数据中不可忽视的重要部分。
“小妞,你今天棒呆啦”,这个句子中的形容词“棒呆啦”指代的到底是赞赏还是讽刺? Amy做了一件很正确的好事时,就是赞赏,但当Amy做了一件糟糕的事情时,就是一种责备和讽刺。在不同场景下,“棒呆啦”一词的含义可以是完全不一样的。
在缺乏对语境和场景的常识下,机器的认知会产生歧义或者是不理解的状况。同时,文本的自动化情感分析也会出现同样的问题,无论是基于机器学习还是词库匹配的情感分类,机器都无法像人一样具有场景和语境的常识,对于文中涉及到的如反讽、暗语等修辞的认知能力还远远不及人类的理解水平。
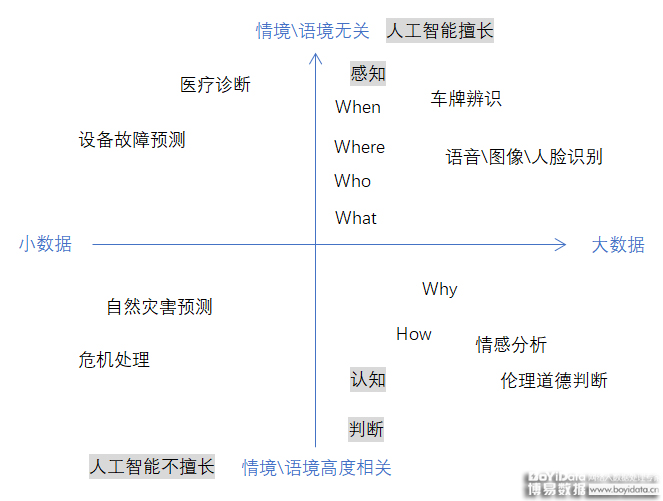
通过重塑5W1H(Who, What, Where, When, Why和How),以此来呈现信息中的关键要素,这也是文本挖掘和分析试图在做的事情。当前,机器是可以对Who, What, Where, When进行挖掘和分析的。例如,以通过人物角色、意见领袖进行Who(谁)的挖掘和分析。通过关键词定义议题的概念,对What(议题)进行挖掘。通过对地点和信息来源渠道进行Where(地点)的挖掘。通过API的方式,实时采集数据,得以实现对于When(何时)时间信息的挖掘。
另外两个关于因果的Why 和 How,在目前的技术水平上,机器基本上是没办法帮我们解决的。
除了对于基本要素5W1H的理解,社会科学研究更需要强调的是变量之间的差异和关系,以及数据背后的因果探索。如何利用人工智能辅助进行多个变量的差异性或者关系的分析?如何提升对文本的感知、认知和判断的能力?这是文本大数据挖掘和分析过程中需要解决的问题。
总结当前舆情分析中存在的问题,过度的程序化和同质化都限制了我们的想象力,解释力和判断力,这样就限制了我们找出更有洞察力的一些发现。所以从感知、认知到判断,重要的不是我们所看到的可视化结果,而是这些结果能带给我们作出判断的信心和确定性。这就需要从数据库的建立——抓取数据开始,到设定分析框架,从测量到分析,应该都是由我们“人”来掌握的,是我们决定机器给我们看什么,而不是机器决定我们看什么。
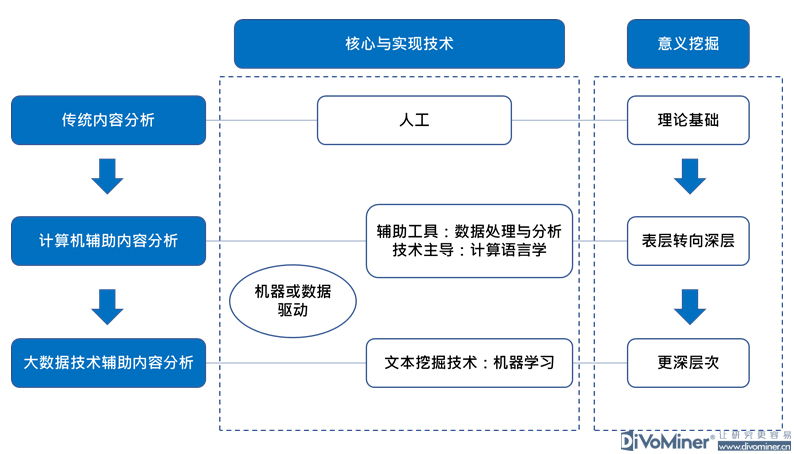
文本大数据挖掘过程经历不同的几个阶段。最初,是通过搜索电子简报,对信息归类。到现在是舆情监测、品牌聆听的做法,从符号/信号到归类资料到信息可视化,目前都已经做了很多的实践和应用。大部分的舆情分析工具都是在这个阶段,有很多运用机器进行自动化分析的系统或程序。
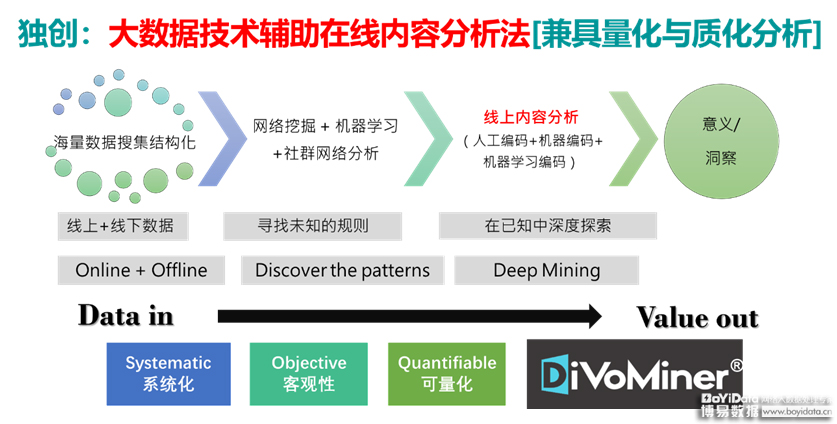
但想要做到监测之后的分析和挖掘,就需要对文本大数据挖掘有全新的理解,即从信息技术(Information technology)的视角转向至社会科学(Social sciences)的视角,也就是说,信息技术应该是辅助文本的挖掘和分析。
运用人机结合,在内容挖掘、语义分析、结构挖掘和社交关系等分析方面,突破感知的层面,提升认知和判断的能力。在充分利用机器辅助的前提下,结合社会科学的概念与方法,以覆盖度、测量和解释这三个重要的维度为重心,聚焦人工智能对文本的感知、认知和判断层面来处理文本大数据所面临的种种问题。
如何实现这种人机结合的机制,将大数据技术与社会科学研究方法结合?
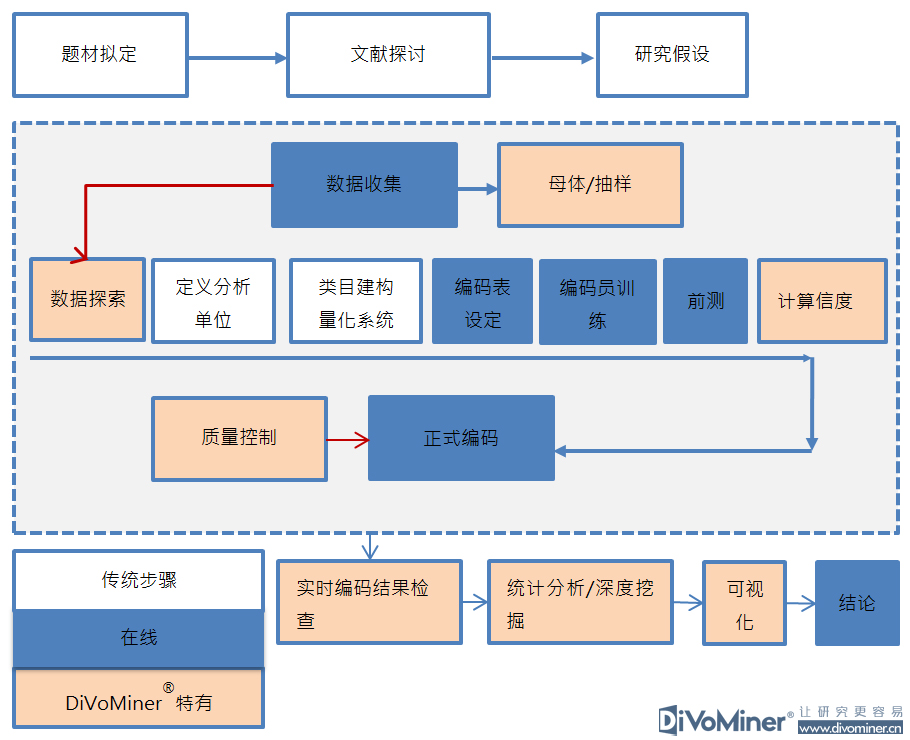
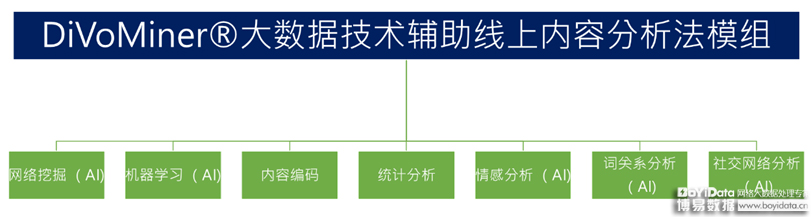
DiVoMiner®大数据技术辅助在线内容分析法模组
为满足社会科学研究对研究质量的需要,平台提供信度测试和质量控制机制,以保证文本挖掘和分析过程的科学和严谨。尤其是内容编码这部分,不同于当前人工智能领域中的“打标签”,主要差别在于内容编码的严谨程序化,除了前测编码外,编码员之间的内在信度和编码质量也都有保障。
正是因为结合了社会科学研究方法,使得研究更具有定制性特征,给予研究人员更多的自主空间进行个性化的研究,解决了当前舆情分析或文本挖掘与分析中面临的问题,例如自动化情感分析中,机器无法解决语境和指向物模糊的问题,在DiVoMiner®上可以通过设定具体的定制化类目,对文本中的变量进行测量。因而通过社会科学研究方法的应用,实现了对于文本中的多变量的差异和关系的挖掘。
参考文献
[1] Marr, B. (2016). What is the difference between artificial intelligence and machine learning? Forbes. Retrieved from:
https://www.forbes.com/sites/bernardmarr/2016/12/06/what-is-the-difference-between-artificial-intelligence-and-machine-learning/#66fdb6862742.
[2] Knowledge@Wharton (2018). Vishal Sikka: Why AI needs a broader, more realistic approach. Retrieved fromhttp://knowledge.wharton.upenn.edu/article/ai-needsbroader- realistic-approach/.
[3] Daugherty, P., Carrel-Billiard, M., & Biltz, M. (2018). Accenture technology vision 2018. Retrieved from. Intelligent Enterprise Unleashed. Accenturehttps://www. accenture.com/t00010101T000000Z__w__/nz-en/_acnmedia/Accenture/next-gen-7/tech-vision-2018/pdf/Accenture-TechVision-2018-Tech-Trends-Report.pdf#zoom=50.
[4] Valin, J. (2018). Humans still needed: An analysis of skills and tools in public relations. Discussion paper. Retrieved from London: Chartered Institute of Public Relations. https://www.cipr.co.uk/sites/default/files/11497_CIPR_AIinPR_A4_v7.pdf.
[5] Searle, J. (1980). Minds, brains and programs. Behavioral and Brain Sciences, 3, 417-457. doi10.1017/S0140525X00005756.
[6] Silver, D.,Huang, A., & Maddison, C. J. ect. (2016). Mastering the game of Go with deep neural networks and tree search. Nature: 484–489. doi:10.1038/nature16961.
[7] 2018AI界的第一件大事记:索菲亚原来是个“骗子”. 新浪财经头条. 2018年8月22日. https://t.cj.sina.com.cn/articles/view/5612652531/14e8a47f300100cm5j
[8] Adam J. Gustein & John Sviokla. 7 Skills That Aren’t About to Be Automated. Harvard Business Review. 2018年7月17日。https://hbr.org/2018/07/7-skills-that-arent-about-to-be-automated?utm_medium=social&utm_campaign=hbr&utm_source=facebook&from=timeline
[9] Parnas, & Lorge, D. . (2017). The real risks of artificial intelligence. Communications of the ACM, 60(10), 27-31.
[10] 张荣显,曹文鸳:《网络舆情研究新路径:大数据技术辅助网络内容挖掘与分析》,《汕头大学学报》(人文社会科学版)2016年,第8期,第111-121页。