
近日,澳门大学张文瑜教授等在SSCI期刊上发表了一篇健康传播领域的论文,核心主题是研究中文语言场景下非传染性疾病(Non-communicable Diseases, NCDs)的新闻报道框架。
研究团队回顾了整整十年(2010-2019)主流新闻媒体报道,利用DiVoMiner®特有的大数据技术辅助在线内容分析法,梳理和描述不同地区各具特点的新闻报道框架,并理解导致框架差异存在的潜在原因,试图为预防和对抗非传染性疾病做出研究贡献。论文中有不少有趣的结果,揭示代谢性类型疾病是新闻报道中最受到关注的类型,而造成非传染性疾病的风险来源分别是压力、吸烟、基因。

按照惯例,接下来小编为大家“拆解”研究过程,介绍研究团队如何完成文本数据分析研究,作出SSCI级别论文!
梳理文献,列明研究问题
根据世界卫生组织WHO的报告,非传染性疾病是基因、生理、环境和行为因素综合作用的结果。心血管疾病、慢性呼吸系统疾病、癌症、糖尿病和中风是非传染性疾病中在全球造成死亡的五大原因。非传染性疾病显然是一个危险的杀手。
论文梳理非传染性疾病的现况及新闻报道的情况,以及综述该领域的框架研究成果,从报道量、风险、后果、归因四个方面提炼研究问题:
-
在中国内地及周边地区的报纸,非传染性疾病的报道量有多少?随着时间的推移,报道量有何变化?How much coverage was devoted to NCDs in mainland China newspapers, and in the neighboring areas, and how did that change over time?
-
非传染性疾病新闻中,如何报道评估风险?How were the NCDs covered along with risk assessment?
-
非传染性疾病新闻中,如何报道代价后果?How were the NCDs covered along with cost consequences?
-
中文新闻报道中是否存在某种疾病与归因的关联,个人层面(片段式结构框架)还是社会层面(主题式结构框架)?What associations, if any, do Chinese news attribute risks with individual‐level (episodic theme) or social‐level frames (thematic theme)?
为回答上述研究问题,论文以跨度十年(2010年1月1日-2019年12月31日)的主流新闻媒体报道为数据选取范围,检索数据关键词包括非传染疾病相关词汇。该研究有两大特点及价值:(1)是以中国内地、港澳台地区为对象的大型中文网络新闻比较分析之一;(2)利用自动化流程收集和解析十年来面对大量中国读者的文本资料。
数据预处理,提高数据相关性及准确度
选取提及关键词至少两次的文本目标样本
在数据样本来源的选取方面,综合考虑媒体属性和影响力,最终选定11家主流新闻媒体,中国内地(4家),香港地区(3家),澳门地区(1家),台湾地区(3家)。
以非传染疾病相关词汇作为检索数据关键词,在中文关键词的拟定方面,由于不同地区在语言表达上存在本土化差异,在设定检索关键词时,充分考虑这一因素,确保数据检索流程的合理性。为提高数据的相关性和准确度,研究团队执行了数据预处理,以关键词次数为依据,如果一篇文章仅提及关键词少于2次,则剔除出样本范围。
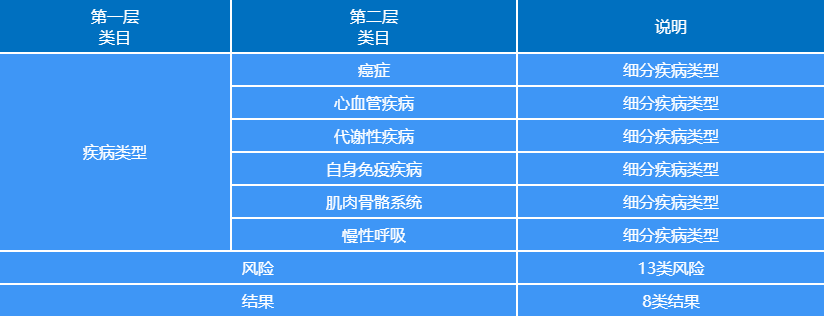
编码簿(Codebook)包括疾病种类、风险评估和疾病后果三部分
编码簿中,考量了26种疾病类型,13种风险评估因素以及8种疾病后果,共计10个类目,涉及54个选项,可谓是相当复杂的内容编码体系,含有跳题设计(想知道类目跳题如何设计?小编后续介绍,敬请关注)。
对于编码簿的制作过程,作者团队在论文中指出,一方面,前期根据研究问题设计出编码簿,涵盖研究需求,另一方面,在数据处理过程中,也可方便地随时调整编码簿。
使用大数据技术辅助在线内容分析法
选取1%样本进行人机结果比对检验
该研究设计利用机器编码批量处理数据,为检验和说明机器编码的准确度,团队随机抽取了1%的数据作为比对样本,由张文瑜教授带领4位经过训练的研究助理完成人工编码的部分,且编码员之间信度达到Cohen’s Kappa = 0.78 (p < 0.001), 95% CI (0.604, 0.948)。最终人机对比一致性达到80%,机器编码结果可接受。

研究结果
过去十年,共有137,175篇新闻报道了非传染性疾病相关的内容,各地区的报道量均是稳定上升趋势。代谢性疾病(如糖尿病、慢性肾脏等)是媒体提及最多的疾病类型。压力、吸烟和基因是风险来源前三位。结果证明,媒体对疾病风险信息的框架性表达,会改变对疾病类型的选择、理解和后果的传播方式。
Leave a Reply