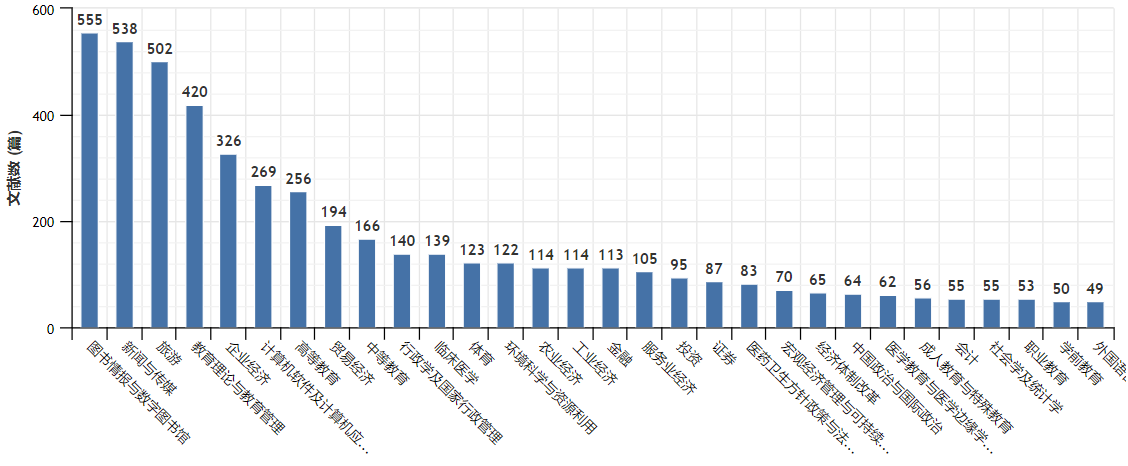
11月24日晚七点,以"文本大数据的研究怎样做得好?"为主题的第五期网络传播三人会热火朝天地在线上举行,本次线上会议由中国新闻史学会网络传播研究史委员会主办,澳门互联网研究学会承办。来自一百多所大专院校、科研机构,近五百位学者和研究生,共同聆听“如何利用大数据技术辅助进行内容分析法”的实战案例。

本次网络传播三人会的主持人及主讲嘉宾分别是:
-
主持人:张荣显博士 – 澳门互联网研究学会会长
引子:文本大数据的研究怎样做得好?如何利用大数据技术辅助内容分析?
-
主讲嘉宾:王丹博士 – 香港浸会大学传理学院高级研究助理级硕士课程兼职讲师
主讲题目:海内外报纸报道“一带一路”及内容分析的研究方法
-
主讲嘉宾:张文瑜博士 – 澳门大学传播系助理教授
主讲题目:文本大数据研究:自动化新闻或社交媒体文本分析为例
-
主讲嘉宾:程萧潇 – 清华大学新闻与传播学院博士候选人
主讲题目:作为数据的文本:大数据技术辅助内容分析中的数据探索与预处理
本期我们首先介绍主持人张荣显博士的发言内容,发言内容以大数据作为开端,介绍了文本大数据的研究路径以及人工智能在文本大数据研究中的不足之处,并提出了大数据技术辅助在线内容分析法(BACA)作为解决这些问题的新路径。
小编将张荣显博士精彩发言进行总结以飨读者,文章较长,分为以下几个部分(整篇大概需要8分钟左右阅读时间):
• 什么是大数据(big data)?
• 什么是文本大数据 (text big data)?
• 文本大数据的研究路径
• 人工智能(AI)于文本大数据研究中的缺陷
• 新路径:大数据技术辅助在线内容分析法
后续小编会继续分享主讲嘉宾的精彩演讲,敬请期待…
一、什么是大数据?
大数据简而言之,从物理上来讲,就是任何超过一台电脑处理能力的庞大数据量,以前是以TB为单位来描述数据量的多少,而现在是以Pb、EB、zb、yB和BB为单位的大量数据。
大数据具有大(数据量庞大:来自四方八面大量的信号),杂(信息多样性:文字、图像、语音、视频、地理位置…)、快(处理速度快:每分每秒变化)和疑(不确定性:数据是否真实)四个特征,当然还要从这些大数据里面能提炼出什么价值出来,这个才是一个最重要也是最需要关注的一个事情。
二、什么是文本大数据?
文本类的数据,包括新闻、社交网络、访谈文字记录、历史档案、文献文档、政策文本、文学作品、领导发言稿,包括文字、图片、视频等等,这些文本数据都具有大、快和杂的特点。从大数据的结构化程度来看,越往下它的结构化程度会越高,越往上,它的非结构化的程度就越高,也就是说不能单纯从Excel中的一个格来看出一个资料中的数字或者意义,这些都是一种非结构化的状态。

三、文本大数据的三个研究路径
1. 文本挖掘
利用人工智能或机器学习的技术,大量把非结构化的文本数据中抽取的分析书。通常我们都说自然语言处理的NLP的技术来进行产出如情绪主题、词语或者词语图及其相关性或者意图等等,并且可以以可视化的方式来呈现这个结果。通常都是利用python或者说语言来实现。如果做文本挖掘,则需要具备编程的能力,如果是研究人员的,特别是负责编程的,则会有很大的主动性,且可以按照自己的研究设计来回答研究问题。
2. 舆情监测
利用现成的自动化的系统,通常是结合自然语言处理跟机器学习的技术,就可以产出标准化的正负面情绪、词云图、来源分布图、声量趋势图等可视化结果。这一种研究者就无需具有编程的能力,但研究者会受限于系统,因为程序已经规范好,则研究者会缺乏主动性,也就难以按照自己的研究设计来回答研究问题。
3. 内容分析
它也是利用现成的可定制化的一种系统,通常是结合自然语言处理跟机器学习的技术,可产出标准化比如刚才所提到的正负面情绪,来源分布图、声量趋势图等可视化结果。有些系统也可以建模,比如说情绪模型,主题聚类模型,词关系模型和社交网络分析模型等。研究者无需懂得编程的能力,它是以内容分析法作为核心的操作流程,且研究者具有完全的主动性,也就是说研究者可以按照自己的研究设计,类目的建构跟量化系统等手段来回答研究问题。
“目前这三种比较主流的文本大数据的研究路径,各有各的好处,也有不同的人在使用不同的方式,要看你面对的是什么样的研究问题,你有的资源是什么”,张荣显博士表示。
四、关于自动化人工智能应用于
文本大数据研究中的问题
人工智能分两类,一类是弱人工智能,利用机器来模拟人的某些特定技能的智能,来处理一些特定场景和应用问题,例如我们经常看到像语音或人脸识别,这类是偏向于感知,也就是识别这个层面的水平。一类是强人工智能,它需要达到有理解的,有认知的,有判断层面的的水平以及几乎接近人类的这种适应水平,当然现在并没有这样子的一个例子出现,这类是比较偏向于认知和判断层面的水平。
而在文本数据的分析当中,如果涉及到认知跟判断层面的时候,会面临中文语境及上文下理的问题,包括很多场景,也包括常识性的东西,不一定能够理解。另外当文本当中有具体指向物,尤其出现多个的时候,还有反讽、暗语、价值判断、及多变量关系等问题出现。
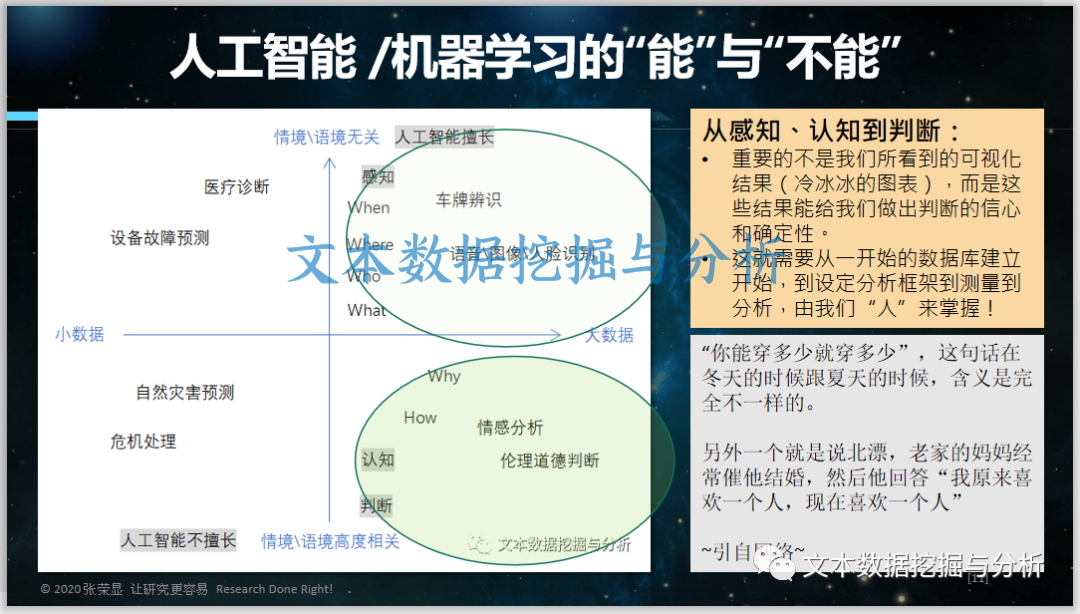
1. 人工智能 /机器学习的“能”与“不能”
人工智能比较擅长感知,也就是识别,但涉及到情感伦理、道德判断、认知判断,人工智能的效果就不是太好。特别是在情景语境高度相关的情况之下,确实有很大对理解和认知判断的能力,比如曾经有人举例说,你能穿多少就穿多少,这句话在冬天的时候跟夏天的时候,它的含义是完全不一样的。另外一个就是北漂老家的妈妈经常催他结婚,然后回答我原来喜欢一个人,现在喜欢一个人,这样的情形就很难去理解。
所以,从感知和认知去判断,重要的不是我们能看到可视化的一个结果,而是这些结果能带来给我们做出判断的信心和确定性有多高,那就是需要从一开始的数据库建立,到设定分析框架,到测量的分析,都由我们"人"来掌控的。
2. 文本大数据的三大挑战
当前最需要关注的处理文本大数据这三大的挑战:
-
覆盖 – 解释数据是否齐全,代表性如何,数据的质量怎么样?
-
测量 – 可以测量什么?如何测量?
-
解释 – 如何分析挖掘以及解释发现?
归根到底,还是3个社会科学研究中永恒的问题:信度!效度!变量之间的差异及关系!
五、新路径:大数据技术辅助在线内容分析法
我们提出新的路径就是大数据技术辅助在线内容分析法(Big-data-tech-aided Online Content Analysis,简称BACA),整个框架就是让海量的数据结构化,从线上或线下提交数据,发现未知的规则,然后在已知当中深度去探索,利用在线内容分析,包括人工编码结合AI编码或者机器学习编码的方式来完成。我们强调就是一个系统化,客观性跟可量化的一种方式。
1. 内容分析法的演变过程
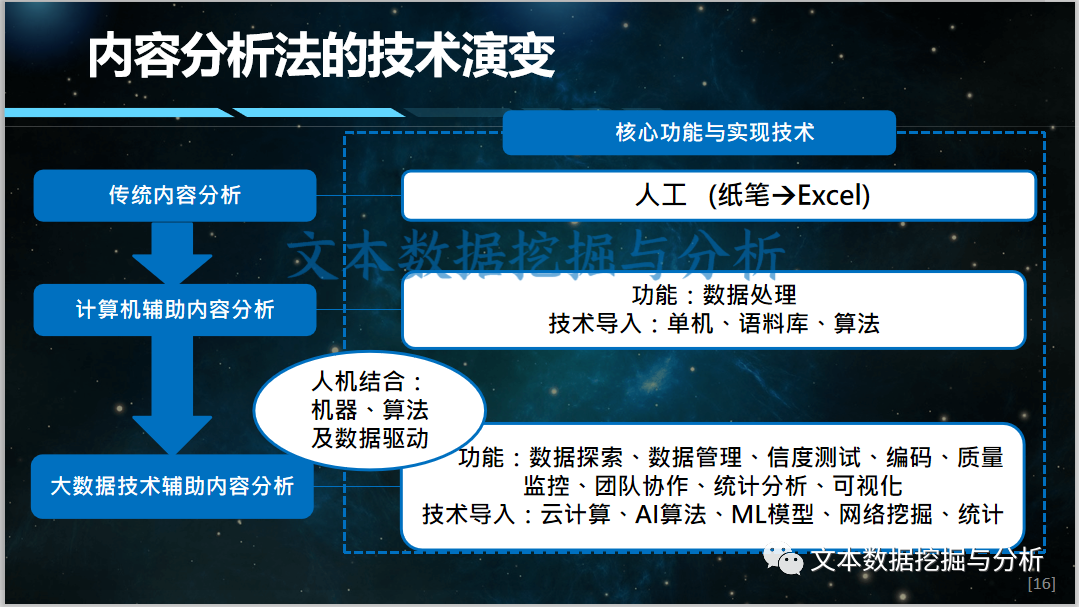
内容分析法的技术演变过程就是从传统内容人工(从纸笔到Excel),计算机辅助内容分析它是辅助做数据处理,包括用一些单机、语料库词库和算法等等的技术导入,大数据技术的内容分析法是人机结合机器算法和数据的驱动来做成,功能包括数据探索,数据管理、信度测试、编码、质量监控、团队协作,统计分析及可视化等等,通过技术的导入,比如云计算、AI算法、ML模型,网络挖掘及统计等来实现。
2. 大数据技术辅助内容分析法的操作流程
通过大数据技术的辅助,可以在线完成整个内容分析法的操作跟分析层面的流程,具体操作流程如下图所示。
3. BACA的研究分析策略
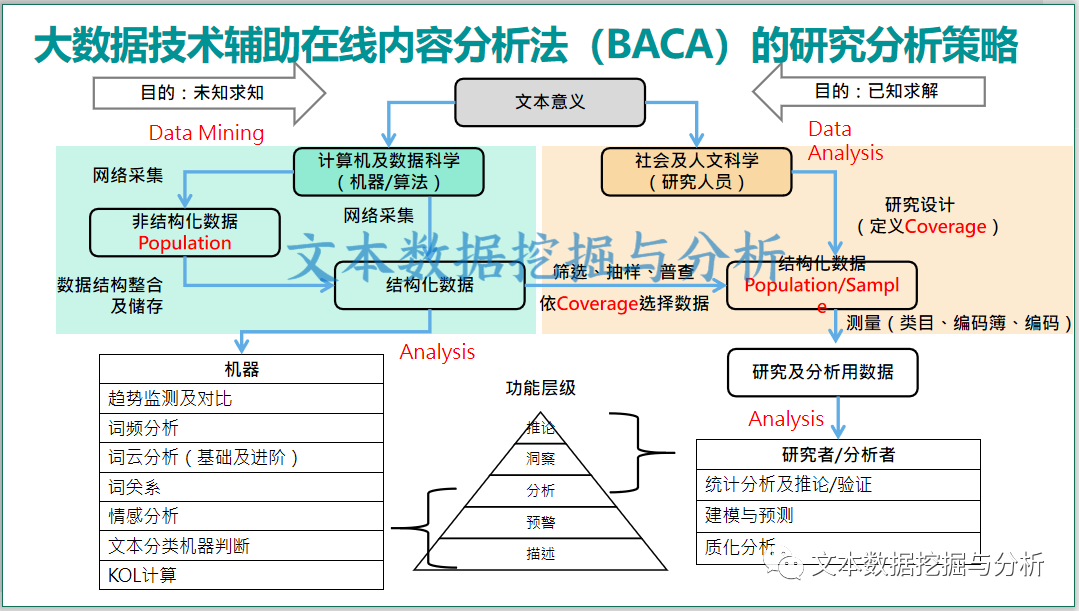
左半蓝色部分是机器技术,右半黄色部分是研究人员,两者相结合在一起,是大数据技术辅助结合人工智慧介入的一个情景。通过人的主动研究,主动思考,把研究设计嵌入到整个分析策略的流程里面,最后用机器产出结果,也可以通过人工去产出结果,或者两者都可以实现的一个研究分析策略流程。
最后,张荣显博士指出,"利用大数据技术辅助在线内容分析法,即使你不会计算机编程,只要你掌握了研究方法的逻辑,遵循学术的规范,都可以主动的按照自己的研究设计,做出“好”的文本大数据研究成果”。