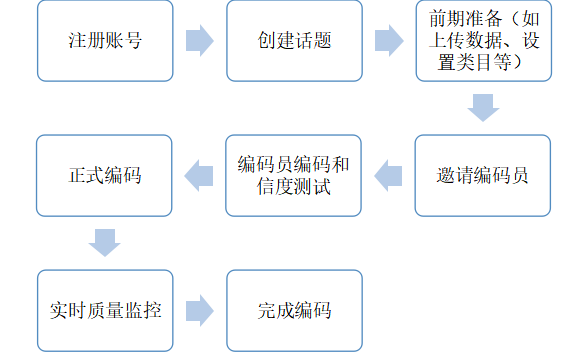
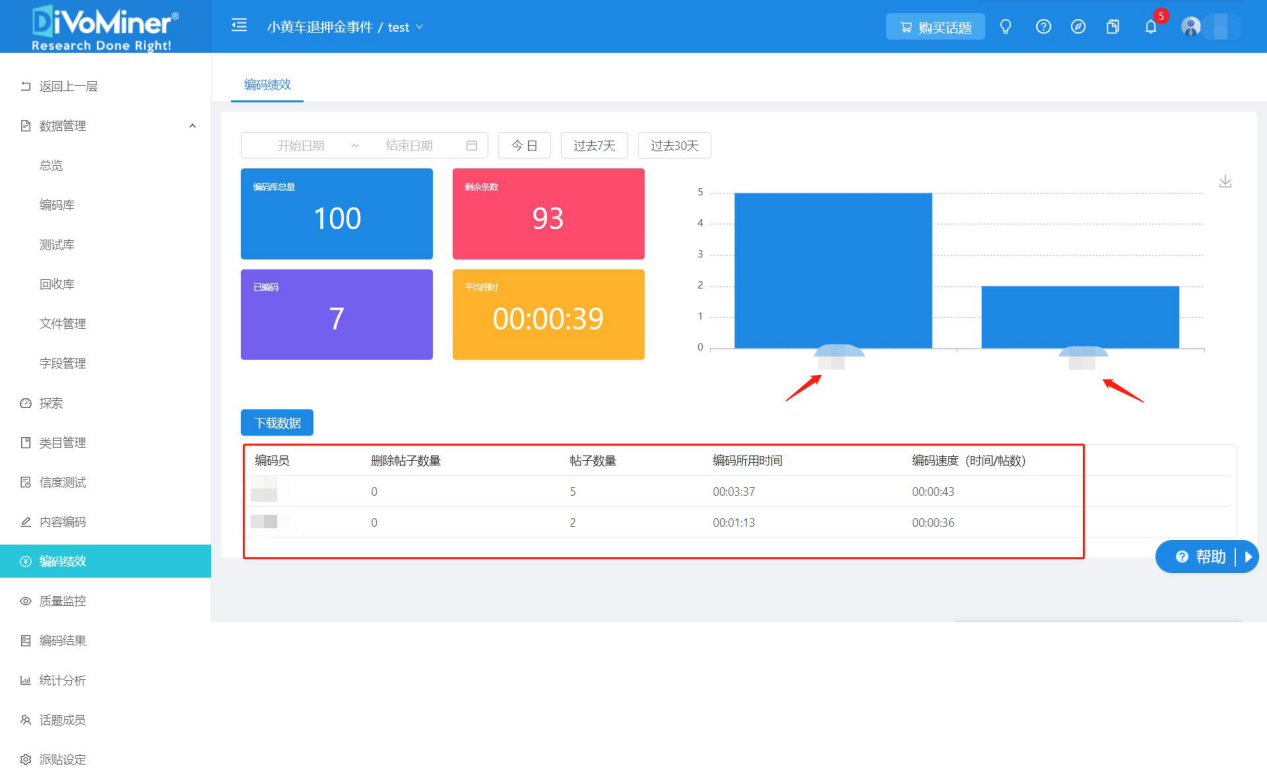
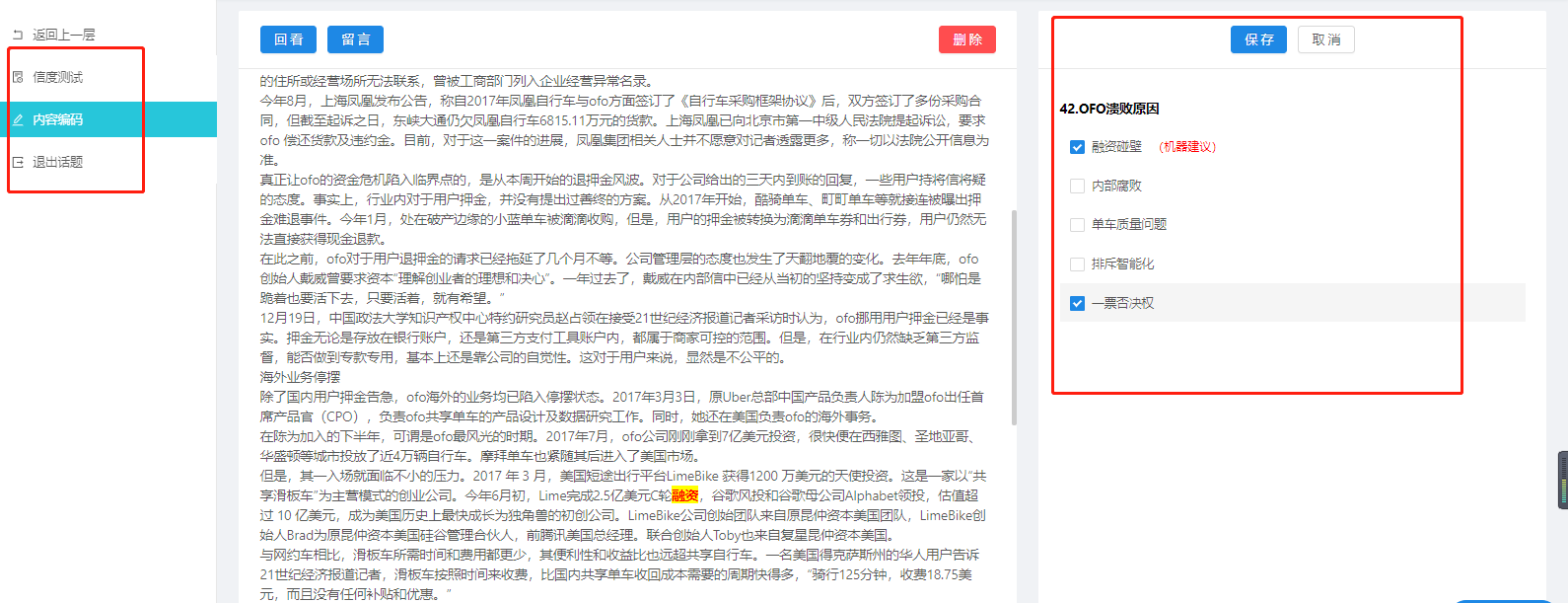
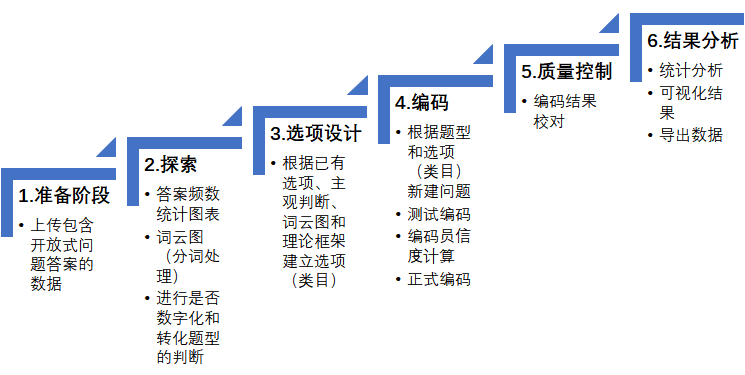
博易代表应邀出席两大重要传播学会议并发表主旨演讲
近日,博易代表应邀出席两大重要传播学会议——亚太传播论坛2020和第五届中国公共关系学术年会,并分别在会上发表主旨演讲。
亚太传播论坛嘉宾与各校师生合照
第五届中国公共关系学术年会与会专家学者合照
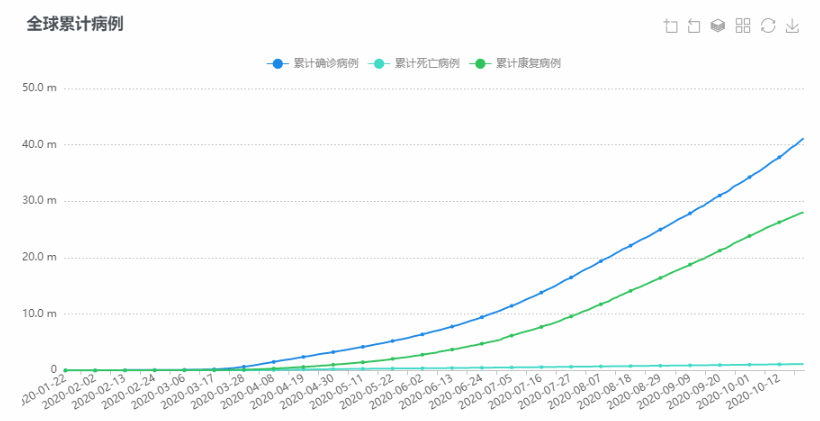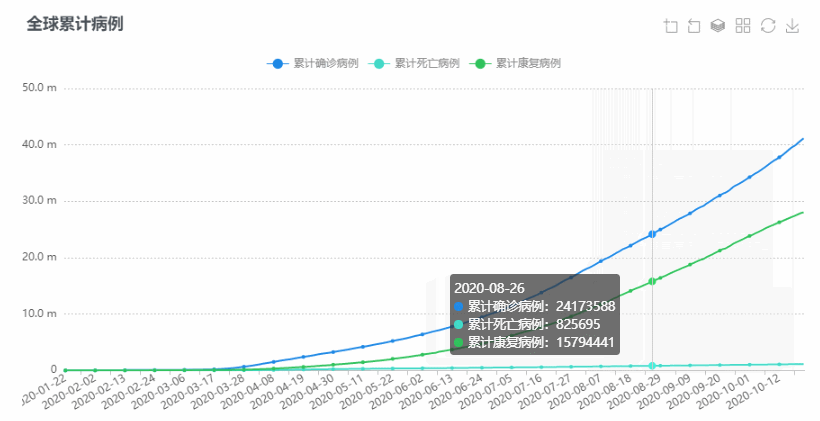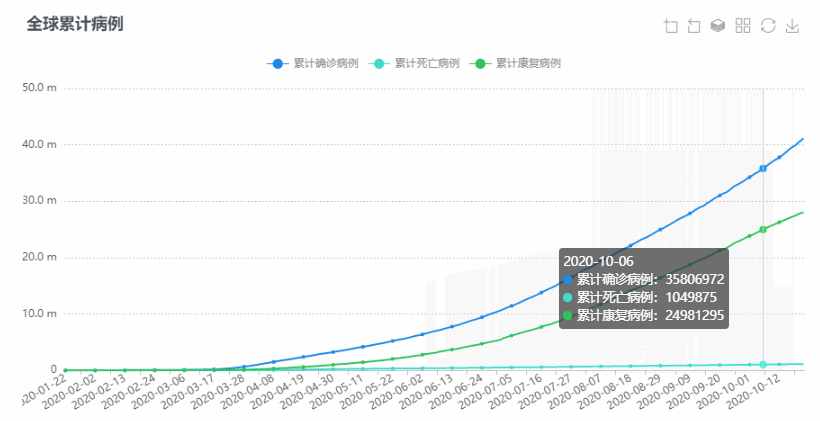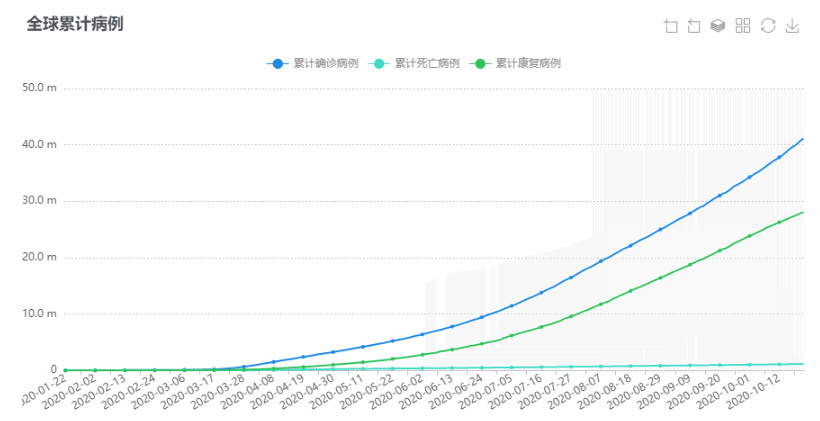
亚太传播论坛2020暨亚太传播论坛联盟成立大会于2020年10月24-25日在珠海横琴·澳门青年创业谷及澳门大学澳门研究中心举行,此会议由亚太传播交流协会(APCEA)主办,是新冠肺炎疫情以来澳门主办最重要的国际传播会议之一。博易代表应邀出席会议并发表题为《为什么大资料在研究方法论中很重要:从传统到创新? 》的主旨演讲,同时以线上直播的方式举行大数据工作坊。
博易数据张荣显博士发表演讲
博易数据高级研究顾问曹文鸳进行大数据工作坊

会议现场
同场,在珠海横琴·澳门青年创业谷,博易数据在现场展示研究型文本大数据挖掘与分析工具DiVoMiner®,受到与会人士的关注和查询。
博易数据代表现场展示DiVoMiner®
同时,博易代表亦受邀出席了另一重要传播学会议——中国新闻史学会公共关系分会第五届中国公共关系学术年会(5thPRSC)暨第十三届公关与广告国际学术论坛(13thPRAD ),并在会上通过线上直播的方式发表题为《关于疫情的文本研究:一个在线内容分析法的思考》的演讲。
博易数据张荣显博士通过线上直播发表主旨演讲
本次学术年会于2020年10月23-25日在兰州举行线上线下同步会议,由中国新闻史学会公共关系分会、华中科技大学新闻与信息传播学院、香港城市大学媒体与传播系、香港浸会大学传理学院、台湾世新大学公共关系暨广告学系、兰州大学新闻与传播学院联合主办,兰州大学新闻与传播学院承办。学术年会主题为“一带一路故事叙事与国家公共关系”,旨在研究一带一路倡议下国家对外传播的理论与实践问题;战略传播与公共关系工作坊主题为“重大疫情危机管理与公共关系” ,旨在讨论突发公共卫生事件中的公关应对与反思。同时,会议还增设第十三届公关与广告国际学术论坛(PRAD)专场,就“国际故事-国家关系的构建与连接”主题展开研讨。
备注:博易数据为易研子公司